最近在做性能优化的工作,很多同事使用了jdk8提供的stream,但是并没有争取正确使用它们,反而造成性能的下降和代码的冗余,并且难以调试和跟踪。这里,为了涨到正确的用法,需要详细了解stream。
Stream介绍
1 | public interface Stream<T> |
据java api中的说明, stream is a sequence of elements supporting sequential and parallel aggregate operations,是支持顺序和并发操作的一组元素。
Sequence of elements: a stream provides an interface to a sequenced set of values of a spectific element type. However, streams don’t actually store elements; they are computed on demand.提供使用一个有序集合的接口,不存储,按需计算。
Source: Streams consume from a data-providing source such as collections, arrays, or I/O resources. 数据来自集合、数组或I/O。
Aggregate operations: Streams support SQL-like operations and common operations from functional programming languages, such as filter, map , reduce, find, match, sorted, and so on。
1 | int sum = widgets.stream() |
为了执行操作,stream 操作会被组成一个stream pipeline,这个stream pipeline包含:
一个数据源(可以是数组、集合、生产者、I/O等)
零个或多个立即执行的操作(将一个stream转换为另一个stream,比如filter(Perdicate))
一个结束操作,产生一个结果或side-effect,如count()和forEach(Consumer)
直到结束操作被初始化,stream中的数据才会被计算,源中的元素被按需消费。
集合和stream,有一些非常相似的地方,但是它们的目的是不同的。集合主要关系的是如何有效管理和获取其中的而数据,而stream不提供方法获取或操作内部的数据,只关心对源的描述和对整个源的计算操作。如果已有的stream操作不满足需求,而可以使用BaseStream.iterator()和BaseStream.spliterator()将stream转换成iterator。
一个stream pipeline,可以被看作对stream source的查询。除非source被明确声明为concurrent modification,如ConcurrentHashMap,否则如果一边查询一边修改stream,会有一些不可预料或错误的后果。
大多数stream操作接受描述用户特定行为的参数,如w->w.getWeight()作为mapToInt的参数。为了保证结果正确,这些行为参数需要满足以下条件:
- 不能修改stream source;
- 大多数情况下必须是无状态的,他们的结果不能依赖于在执行stream pipeline时会改变的状态。
这些参数大多数情况下时一个funtional interface,比如Function,或lambda表达式或方法引用。除非特别声明,这些参数不能为null。
一个stream只能被操作一次,不能同时做为两个或多个pipeline的源,可能会抛出IllegalStateException。然而,由于一些流操作可能返回其接收器而不是新的流对象,所以在所有情况下可能无法检测到重用。
使用
在工作中,大多数情况下,开发人员根据一个list或set生成一个stream并进行一些操作,如
1 | list.stream.map(entity->entity.getId()).collect(toSet()); |
或执行一些并发操作:
1 | list.parallelStream().forEach(entity-> { |
有时候需要异步执行并等待支持完成,这时候容易写下以下代码:
1 | Integer[] integers = new Integer[1000]; |
在代码中,使用map将integer进行异步处理,并返回Completable对象,在forEach中执行Completable.join。下面是日志,从日志上看,所有的数据都被顺序处理的,并没有真正被多线程处理。
1 | [11:54:19:539] [INFO] - ForkJoinPool.commonPool-worker-1 - begin to process integer:0 |
原因在于这是一个顺序的stream,在流被处理时,对每个一个数据执行所有的操作,如对于integer,先执行map操作,将数据放入异步线程池中处理,然后执行forEach中的CompletableFuture.join操作,所以只有当前一个数据被完全处理完,第二个数据才开始被执行。
修改代码,将CompletableFuture收集到集合中,然后对每个对象执行join,等待所有数据被处理完成。
1 | Integer[] integers = new Integer[1000]; |
此时的日志显示数据被多线程处理了。代码中没有设置线程池,默认使用ForkJoinPool.commonPool,线程池的最大线程数为7。
操作
stream接口定义了很多操作,这些操作可以被分为两类:
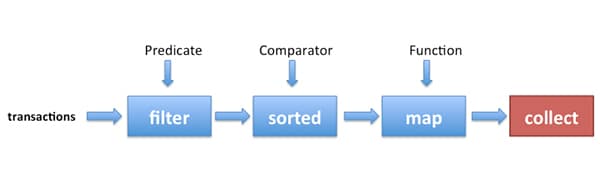
- filter, sorted, map,可以被串联形成pipeline,这些操作被称为intermediat operations,他们的返回类型为stream。
- collect,结束pipeline,返回结果,被称为terminal operations,返回list, integer,甚至void,但不是stream。
intermedia operations不会执行任何处理,直到stream pipleline上被添加terminal operation。intermediate operations can usually be “merged” and processed into a single pass by the terminal operation.
1 | List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8); |
1 | filtering 1 |
上例中limit(2)使用short-circuiting,因此实际运行时,只需要处理一部分流就可以返回结果。